Building apps is too hard. Even skilled programmers who don’t specialize in app development struggle to build simple interactive tools. We think that a lot of what makes app development hard is managing state: reacting and propagating changes as the user takes actions.
We’re exploring a new way to manage data in apps by storing all app state—including the state of the UI—in a single reactive database. Instead of imperatively fetching data from the database, the user writes reactive queries that update with fresh results whenever their dependencies change.
As an initial prototype, we have built a reactive layer around SQLite that populates data in a React app, and used it to build a music library app. We’ve learned a lot from trying to apply our big vision to a real app; this essay shares some of what we’ve learned and where we want to take the project next.
Even in our limited prototype, we’ve found thinking of apps as queries to be a powerful frame, opening up new approaches to debugging, persistence, and cross-app interoperability. We’ve also learned hard lessons about the limitations of SQL and the performance challenges of the web platform.
Together, our ideas and experiments suggest that we could take this frame even further. We sketch a vision for thinking of every layer of an app, from the event log to the pixels on the screen, as pieces of a single large query. Furthermore, we believe that the key components for building such a system already exist, in tools developed for incremental view maintenance and fine-grained provenance tracking. While we’ve only scratched the surface so far, we think that a framework based on these ideas would be both possible to build and radically simpler to use.Introduction
Today, building interactive apps is so hard that it’s a specialized skill even among software developers. Skilled technical computer users, including scientists and systems programmers, struggle to make simple apps, while less technical end-users are disempowered entirely. We think that it should be possible to make app development radically more accessible to experts and novices alike.
Consider a music player app like iTunes. The core user interface is simple: it manages a music collection and displays a variety of custom views organized by various properties like the album, artist, or genre. However, the conceptual simplicity of the UI doesn’t mean that the app is actually easy to build. We think that there are millions of these “data-centric” apps that don’t exist because they are too hard to build relative to the size of their audience.
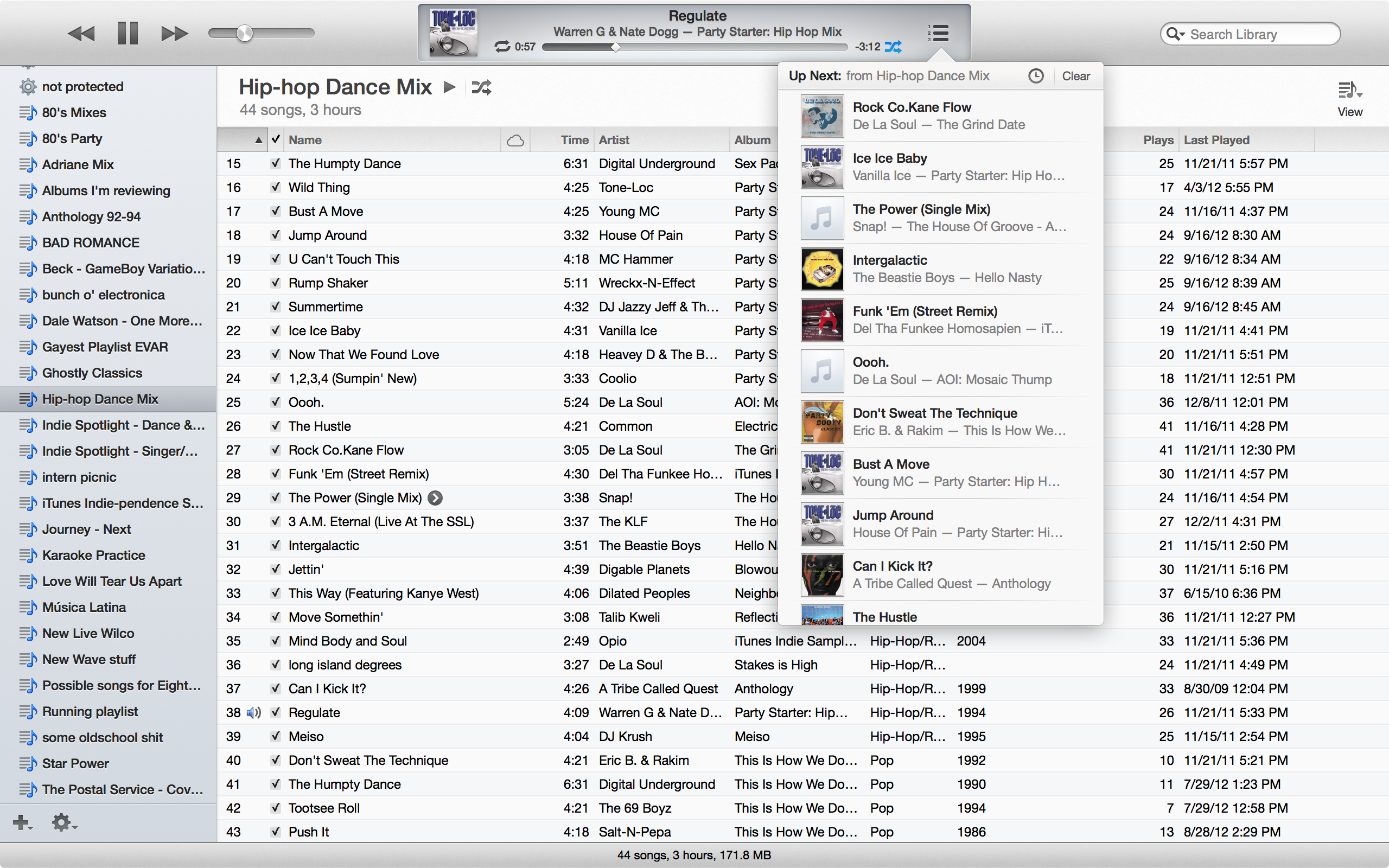
iTunes is a representative example of a data-centric app.
In data-centric apps, much of the complexity of building and modifying the app comes from managing and propagating state.
Here's an interesting thought experiment.
Many software developers think that it is much easier to build command line tools than GUI apps, or even text-user interface (TUI) apps.
Why is that?
One answer is that command line tools tend to be stateless in between user commands.
A user gives the program some instructions, and it executes them, then discards all of the hidden state before returning control to the user.
In contrast, most apps have some kind of persistent state—often quite a lot—that needs to be maintained and updated as the user takes actions.
In some sense, state management is the main thing that makes an app an app, and distinguishes app development from related tasks like data visualization.
Most of what iTunes does is display a bunch of dynamic state and provide tools for editing it.
What song is playing, and what's in the queue?
What songs are in this playlist, and in what order?
There's a good chance that your own favourite GUI app--a slide editor, an exercise tracker, a note taking tool--has the same basic structure.
We’ve found that state management tends to be a colossal pain. In a traditional desktop app, state is usually split between app’s main memory and external stores like filesystems and embedded databases, which are cumbersome to coordinate. In a web app, the situation is even worse: the app developer has to thread the state through from the backend database to the frontend and back. A “simple” web app might use a relational database queried via SQL, an ORM on a backend server, a REST API used via HTTP requests, and objects in a rich client-side application, further manipulated in Javascript:
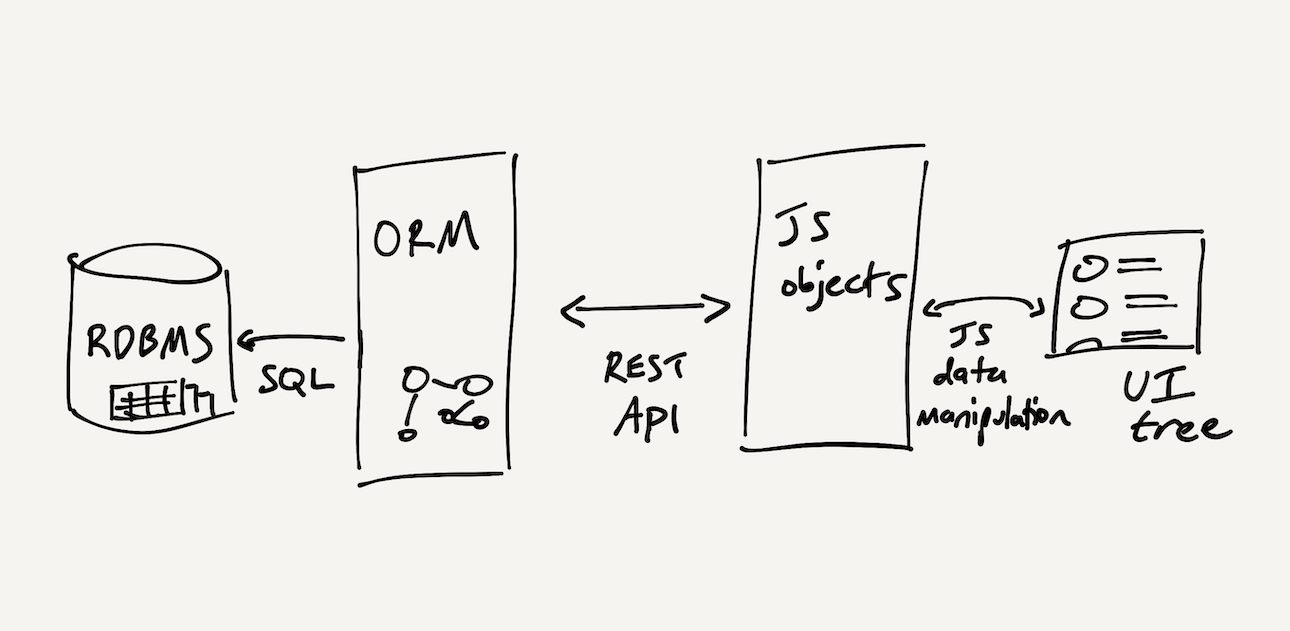
The need to work across all these layers results in tremendous complexity. Adding a new feature to an app often requires writing code in many languages at many layers. Understanding the behavior of an entire system requires tracking down code and data dependencies across process and network boundaries. To optimize performance, developers must carefully design caching and indexing strategies at every level.
How might we simplify this stack?
We think one promising pattern is a local-first architecture where all data is stored locally on the client, available to be freely edited at any time, and synchronized across clients whenever a network is available. In addition to benefits for developers, a local-first architecture also helps end-users by giving them more ownership and control over their own data, and allowing apps to remain usable when the network is spotty or nonexistent. This architecture allows rich, low-latency access to application state, which could unlock totally new patterns for managing state. If an app developer could rely on a sufficiently powerful local state management layer, then their UI code could just read and write local data, without worrying about synchronizing data, sending API requests, caching, or other chores of app development.
This raises the question: what might such a powerful state management layer look like? It turns out that researchers and engineers have worked for decades on systems that specialize in managing state: databases! The word “database” may conjure an image of a specific kind of system, but in this essay we use the word expansively to refer to any system that specializes in managing state. A traditional relational database contains many parts: a storage engine, a query optimizer, a query execution engine, a data model, an access control manager, a concurrency control system, all of which provide different kinds of value. In our view, a system doesn't even need to offer long-term persistence to be called a database. We think that many of the technical challenges in client-side application development can be solved by ideas originating in the databases community. As a simple example, frontend programmers commonly build data structures tailored to looking up by a particular attribute; databases solve precisely the same problem with indexes, which offer more powerful and automated solutions. Beyond this simple example, we see great promise in applying more recent research on better relational languages for expressing computations, and incremental view maintenance for efficiently keeping queries updated.
In the Riffle project, our goal is to apply ideas from local-first software and databases research to radically simplify app development. In this essay, we start by proposing some design principles for achieving this simplification. We think that a relational model, fast reactivity, and unified approach that treats all state the same way form a potent trio, which we call the reactive relational model. We’ve also built a concrete prototype implementing this idea using SQLite and React, and have used the prototype to build some apps that we can actually use.
So far, we’ve found promising signs that the reactive relational model can help developers more easily and debug apps, produce better apps for end-users, and offers intriguing possibilites for data-centric interoperability between apps. We’ve also encountered challenges from trying to build toward this vision using existing tools. We conclude by sketching a more radical approach to representing an entire full-stack application as a single reactive relational query, which we think could be a big step towards making app development radically easier for both experts and novices.
Principles
Declarative queries clarify application structure
Most applications have some canonical, normalized base state which must be further queried, denormalized, and reshaped before it can populate the user interface. For example, in a music app, if a list of tracks and albums is synced across clients, the UI may need to join across those collections and filter/group the data for display.
In existing app architectures, a large amount of effort and code is expended on collecting and reshaping data. A traditional web app might first convert from SQL-style tuples to a Ruby object, then to a JSON HTTP-response, and then finally to a frontend Javascript object in the browser. Each of these transformations is performed separately, and there is often considerable developer effort in threading a new column all the way through these layers.
In a local-first application, all the queries can instead happen directly within the client. This raises the question: how should those queries be constructed? We suspect that a good answer for many applications is to use a relational query model directly in the client UI. As we'll discuss throughout this piece, SQL as a specific instantiation of the relational model has some shortcomings. This has often led to adding layers around SQL, like ORMs and GraphQL. However, in principle, a sufficiently ergonomic replacement for SQL could eliminate the need for such additional layers. Anyone who has worked with a relational database is familiar with the convenience of using declarative queries to express complex reshaping operations on data. Declarative queries express intent more concisely than imperative code, and allow a query planner to design an efficient execution strategy independently of the app developer's work.
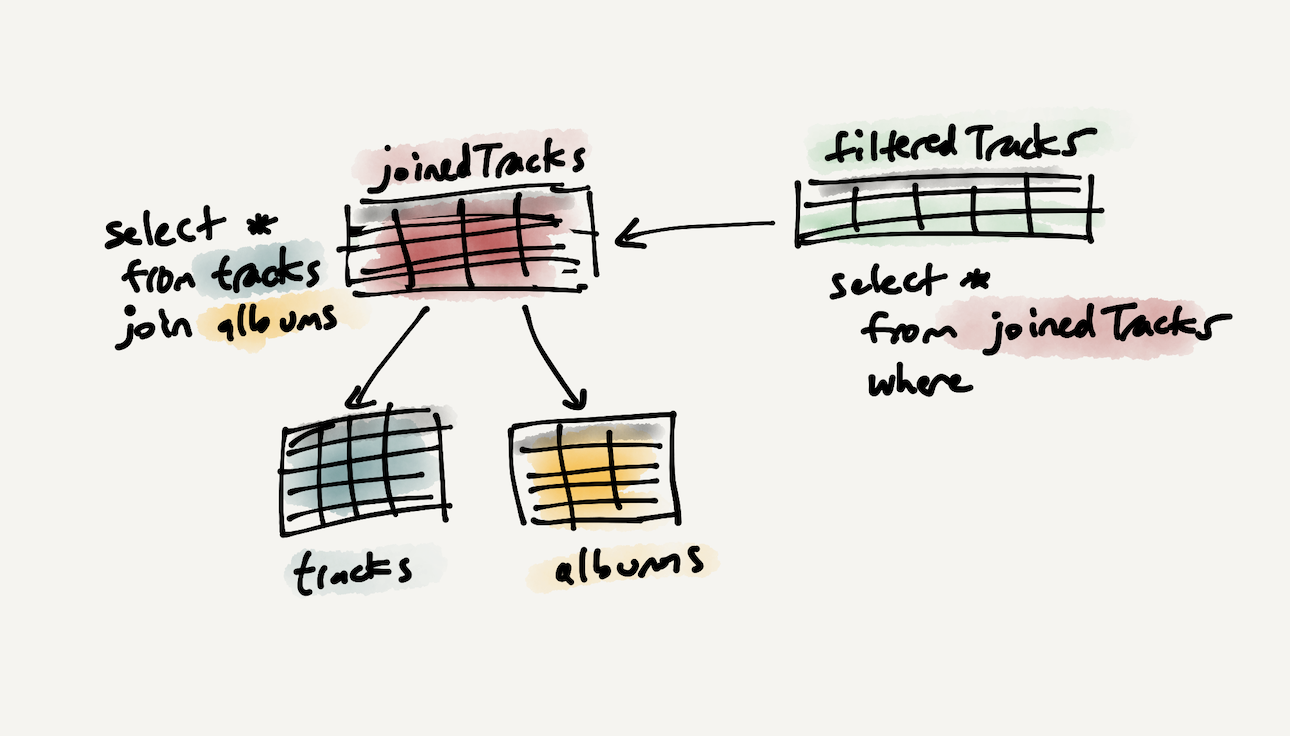
A music app stores a list of tracks in a normalized format with separate tables for tracks and albums, which are related by a foreign key. The app reads the data in a joined format so that a user can filter on any track attribute, including the album title. The relational query model makes these data dependencies clearer than other approaches, like nested API calls.
This is an uncontroversial stance in backend web development where SQL is commonplace. It’s also a typical approach in desktop and mobile development—many complex apps use SQLite as an embedded datastore, including Adobe Lightroom, Apple Photos, Google Chrome, and Facebook Messenger.
However, we’ve observed that the primary use of database queries is to manage peristence: that is, storing and retrieving data from disk. We imagine a more expansive role for the relational database, where even data that would normally be kept in an in-memory data structure would be logically maintained “in the database”. In this sense, our approach is reminiscent of tools like Datascript and LINQ which expose a query interface over in-memory data structures. There’s also a similarity to end-user focused tools like Airtable: Airtable users express data dependencies in a spreadsheet-like formula language that operates primarily on tables rather than scalar data.
Fast reactive queries provide a clean mental model
A reactive system tracks dependencies between data and automatically keeps downstream data updated, so that the developer doesn’t need to manually propagate change. Frameworks like React, Svelte, and Solid have popularized this style in web UI development, and end-users have built complex reactive programs in spreadsheets for decades.
However, database queries are often not included in the core reactive loop. When a query to a backend database requires an expensive network request, it’s impractical to keep a query constantly updated in real-time; instead, database reads and writes are modeled as side effects which must interact with the reactive system. Many applications only pull new data when the user makes an explicit request like reloading a page; keeping data updated in realtime usually requires a manual approach to sending diffs between a server and client. This limits the scope of reactivity: the UI is guaranteed to show the latest local state, but not the latest state of the overall system.
In a local-first architecture where queries are much cheaper to run, we can take a different approach. The developer can register reactive queries, where the system guarantees that they will be updated in response to changing data.
This approach is closely related to the document functional reactive programming (DFRP) model introduced in Pushpin, except that we use a relational database rather than a JSON CRDT as our data store, and access them using a query language instead of a frontend language like Javascript.
We can also create reactive derived values from our data outside of the tree of UI elements, as in React state management frameworks like Jotai and Recoil.
This is also related to cloud reactive datastores like Firebase and Meteor, but storing data on-device rather than on a server enables fundamentally different usage patterns.
Reactive queries can also depend on each other, and the system will decide on an efficient execution order and ensure data remains updated. The UI is guaranteed accurately reflect the database's contents, without the developer needing to manage side effects.
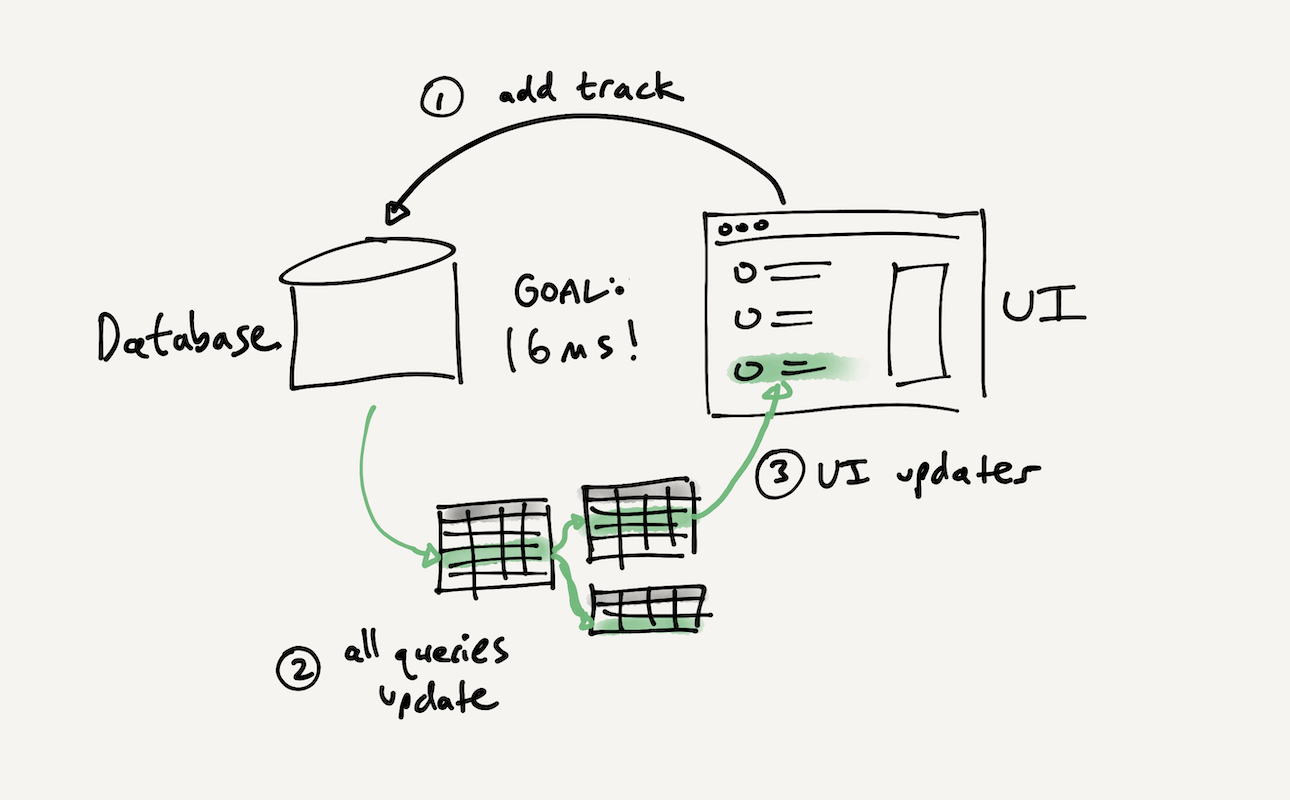
When queries happen locally, they are fast enough to run in the core reactive loop. In the span of a single frame (16ms on a 60Hz display, or even 8ms on modern 120Hz display), we have enough time to ① write a new track to the database, ② re-run the queries that change because of that new track, and ③ propagate those updates to the UI. From the point of view of the developer and user, there was no intermediate invalid state.
Low latency is a critical property for reactive systems. A small spreadsheet typically updates instantaneously, meaning that the user never needs to worry about stale data; a few seconds of delay when propagating a change would be a different experience altogether. The goal of a UI state management system should be to converge all queries to their new result within a single frame after a write; this means that the developer doesn’t need to think about temporarily inconsistent loading states, and the user gets fast software.
This performance budget is ambitious, but there are reasons to believe it's achievable with a local relational database.
As we discussed our ideas with working app developers, we found that many people who work with databases in a web context has an intuition that databases are slow.
This is striking because even primitive databases like SQLite are fast on modern hardware: many of the queries in our demo app run in a few hundred microseconds on a few-years-old laptop.
We hypothesize this is because developers are used to interacting with databases over the network, where network latencies apply. Also, developer intuitions about database performance were developed when hardware was much slower—modern storage is fast, and often datasets fit into main memory even on mobile devices. Finally, many relational database management systems aren't built for low latency—many databases are built for analytics workloads on large data sets, where a bit of extra latency is irrelevant to overall performance.
The database community has spent considerable effort making it fast to execute relational queries; many SQLite queries complete in well under one millisecond. Furthermore, there has been substantial work on incrementally maintaining relational queries (e.g., Materialize, Noria, SQLive, and Differential Datalog) which can make small updates to queries much faster than re-running from scratch.
Managing all state in one system provides greater flexibility
Traditionally, ephemeral “UI state,” like the content of a text input box, is treated as separate from “application state” like the list of tracks in a music collection. One reason for this is performance characteristics—it would be impractical to have a text input box depend on a network roundtrip, or even blocking on a disk write.
With a fast database close at hand, this split doesn’t need to exist. What if we instead combined both “UI state” and “app state” into a single state management system? This unified approach would help with managing a reactive query system—if queries need to react to UI state, then the database needs to somehow be aware of that UI state. Such a system could also present a unified system model to a developer, e.g. allow them to view the entire state of a UI in a debugger.
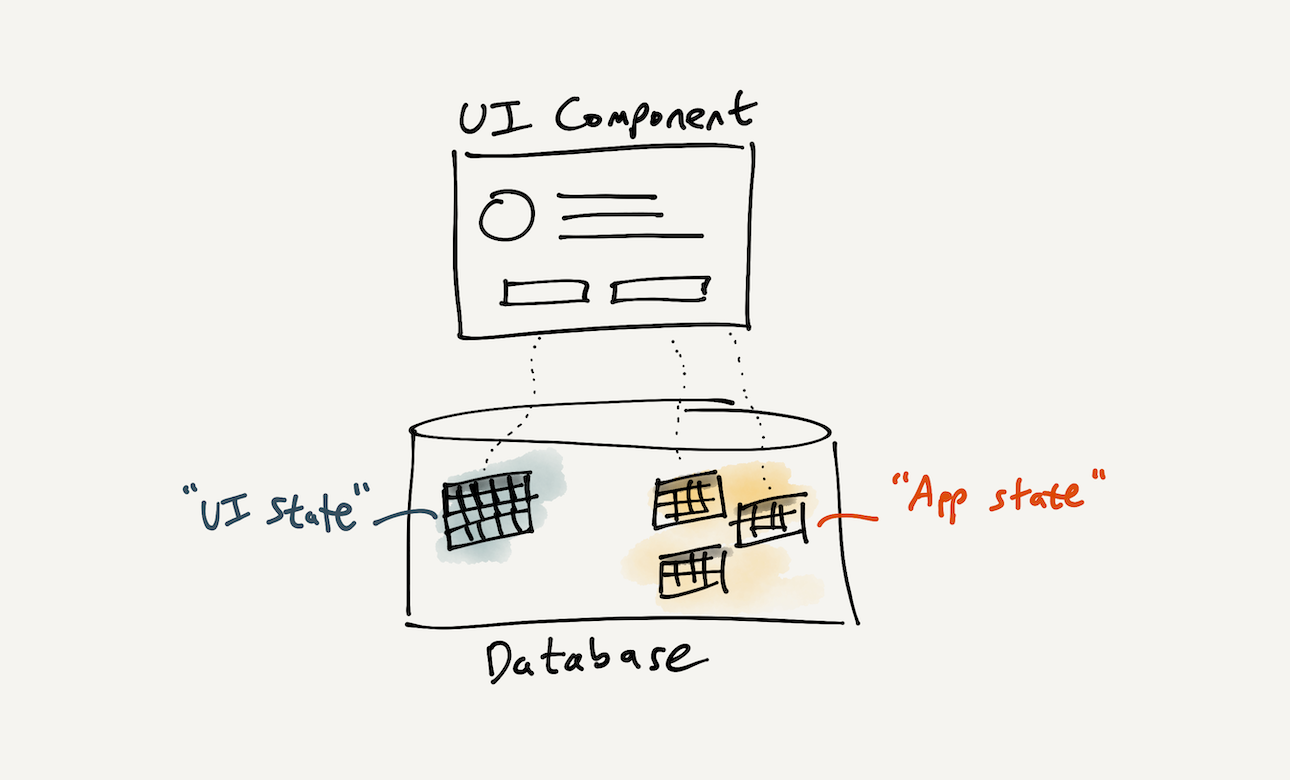
Conceptually, the state of each UI element is stored in the same reactive database as the normal app state, so the same tools can be used to inspect and modify them. This makes it especially easy to manage interactions between UI elements and core objects in the app’s domain (e.g., tracks and albums in a music app).
It would still be essential to configure state along various dimensions: persistence, sharing across users, etc.
Databases are hardly new technology, so it's interesting to wonder about why they've largely not been adopted to manage state in the way that we imagine.
We aren't experts on database history, though, so this is somewhat speculative.
We pin part of the blame on SQL: as we learned while building our prototype, it's just not terribly ergonomic for many of the tasks in app development.
We also think that there's something of a chicken-and-egg problem.
Because databases don't have the prominent role in app development that we imagine they could, no one appears to have built a database with the right set of performance tradeoffs for app-based workloads.
For example, few databases are optimized for the low latencies that are necessary for interactive apps.
Finally, we think that it might not have been possible to use a database for storing UI-specific, ephemeral state when many modern UI paradigms were developed.
However, modern hardware is just really, really fast, which opens up new architectures.
But in a unified system, these could just be lightweight checkboxes, not entirely different systems.
This would make it easy to decide to persist some UI state, like the currently active tab in an app. UI state could even be shared among clients—in real-time collaborative applications, it's often useful to share cursor position, live per-character text contents, and other state that was traditionally relegated to local UI state.
Prototype system: SQLite + React
We built an initial prototype of Riffle: a state manager for web browser apps. For this prototype, our goal was to rapidly explore the experience of building with local data, so we reduced scope by building a local-only prototype which doesn’t do any multi-device sync. Syncing a SQLite database across devices is a problem others have solved (e.g., James Long’s CRDT-based approach in Actual Budget) so we’re confident it can be done. We also have further ideas for thoughtfully designing sync systems which we’ll share in our next essay.
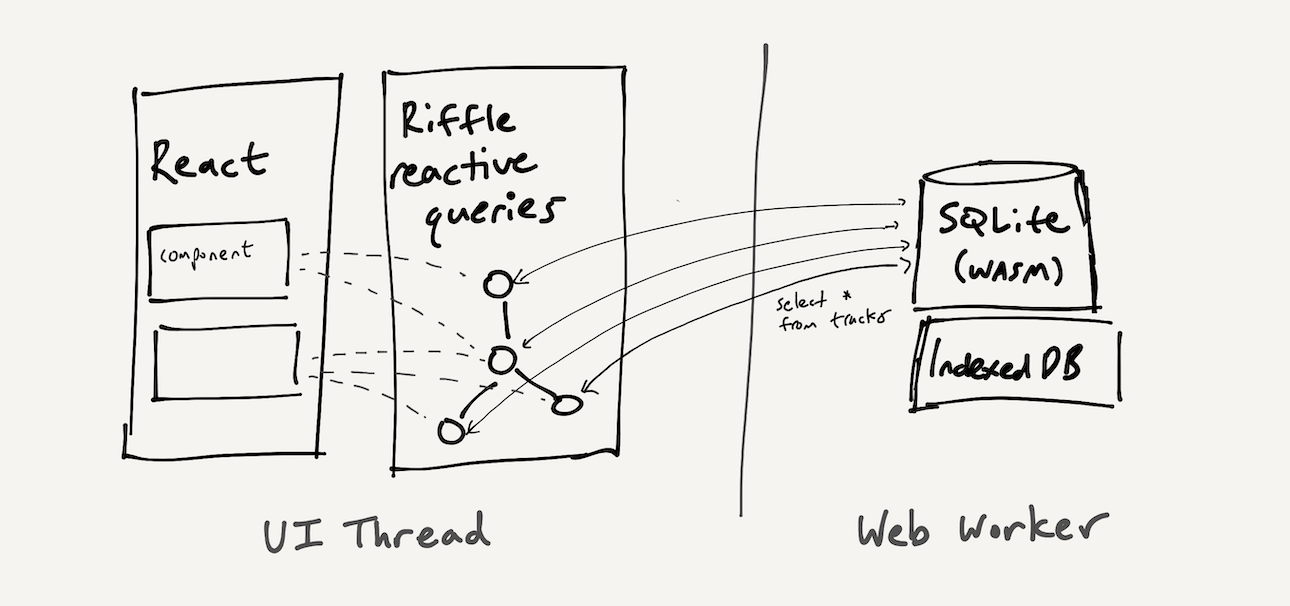
Our prototype is implemented as a reactive layer over the SQLite embedded relational database. The reactive layer runs in the UI thread, and sends queries to a SQLite database running locally on-device. For rendering, we use React, which interacts with Riffle via custom hooks.
To run apps in the browser (pictured below), we run the SQLite database in a web worker and persist data to IndexedDB, using SQL.js and absurd-sql. We also have a desktop app version based on Tauri (an Electron competitor that uses native webviews instead of bundling Chromium); in that architecture we run the frontend UI in a webview and run SQLite in a native process, persisting to the device filesystem.
In this section, we’ll demo our prototype by showing how to use it to build a simplified iTunes-style music app. Our music collection is a very natural fit for a relational schema containing several normalized tables linked by foreign keys. Each track has an ID and name, and belongs to exactly one album:
tracks
| id | name | album_id | artist_id |
|---|---|---|---|
| 1 | If I Ain’t Got You | 11 | 21 |
| 2 | Started From the Bottom | 12 | 22 |
| 3 | Love Never Felt So Good | 13 | 23 |
albums
| id | name |
|---|---|
| 11 | The Diary of Alicia Keys |
| 12 | Nothing Was The Same |
| 13 | XSCAPE |
artists
| id | name |
|---|---|
| 21 | Alicia Keys |
| 22 | Drake |
| 23 | Michael Jackson |
A first reactive query
In our app, we’d like to show a list view, where each track has a single row showing its album and artist name. Using SQL, it’s straightforward to load the name for each track, and to load the name of its album and artist. We can do this declaratively, specifying the tables to join separately from any particular join strategy.
select
tracks.name as name,
albums.name as album
artists.name as artist
from tracks
left outer join albums on tracks.album_id = albums.id
left outer join artists on tracks.artist_id = artists.idThis query will produce results like this:
| name | album | artist |
|---|---|---|
| If I Ain’t Got You | The Diary of Alicia Keys | Alicia Keys |
| Started From the Bottom | Nothing Was The Same | Drake |
| Love Never Felt So Good | XSCAPE | Michael Jackson |
Once we’ve written this query, we’ve already done most of the work for showing this particular UI. We can simply extract the results and use a JSX template in a React component to render the data. Here’s a simplified code snippet:
import { db, useQuery } from 'riffle'
const tracksQueryString = sql`
select
tracks.name as name,
albums.name as album_name
artists.name as album_name
from tracks
left outer join albums on tracks.album_id = albums.id
left outer join artists on tracks.artist_id = artists.id
`
// use hardcoded SQL string for our query
const tracksQuery = db.query(() => tracksQueryString)
const TrackList = () => {
// Subscribe to reactive query
const tracks = useQuery(tracksQuery)
return <table>
<thead>
<th>Name</th><th>Album</th><th>Artist</th>
</thead>
<tbody>
{tracks.map(track => <tr>
<td>{track.name}</td><td>{track.album}</td><td>{track.artist}</td>
</tr>)}
</tbody>
</table>
}We can also represent this component visually. Currently it contains a single SQL query which depends on some global app state tables, as well as a view template.
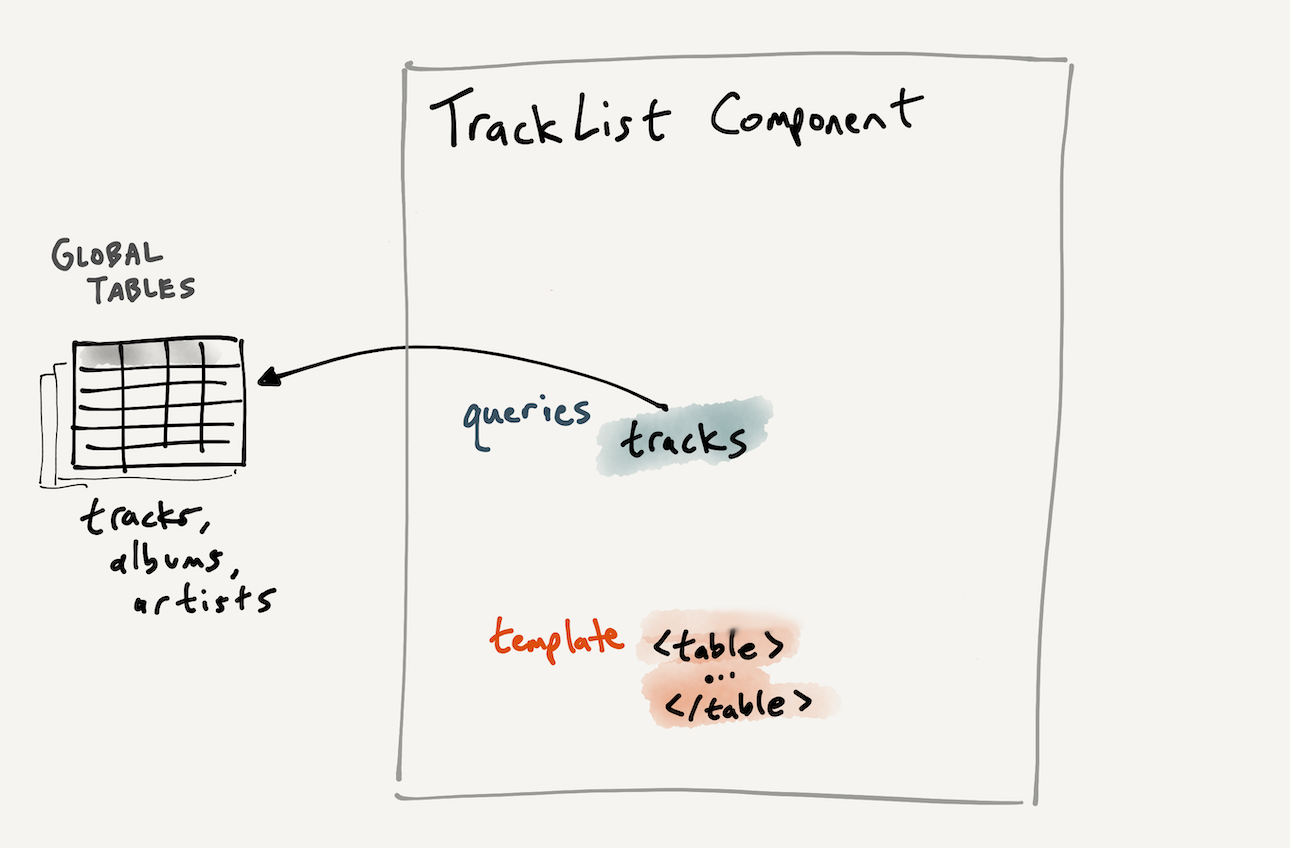
The UI looks like this:
Importantly, this query doesn’t just execute once when the app boots. It’s a reactive query, so any time the relevant contents of the database change, the component will re-render with the new results. Currently our prototype implements the most naive reactivity approach: re-running all queries from scratch any time their dependencies change. This still turns out to usually be fast enough because SQLite can run many common queries in under 1 millisecond. Once it becomes necessary, we plan to introduce table-granularity reactivity as an improved approach. For example, when we add a new track to the database, the list updates automatically.
Reacting to UI state in the database
Next, let’s add some interactive functionality by making the table sortable when the user clicks on the column headers. The current sort property and direction represents a new piece of state that needs to be managed in our application. A typical React solution might be to introduce some local component state with the useState hook. But the idiomatic Riffle solution is to avoid React state, and instead to store the UI state in the database.
Our prototype has a mechanism for storing local state associated with UI components. Each type of component gets a relational table, with a schema that defines the local state for that component. Each row of the table is associated with a specific instance of the component, identified by a unique ID called the component key.
How are component instance IDs chosen? An app developer can choose from several strategies:
- Ephemeral: every time React mounts a new component instance, generate a fresh random ID. This replicates the familiar behavior of React’s local state. Once a component unmounts, we can safely garbage collect its state from the table.
- Singleton: always assign the same ID, so that the table only has one row. This is useful for a global
Appcomponent, or any situation where we want all instances of the component type to share state. - Custom: The developer can choose a custom key to identify a component across mounts. For example, a track list might be identified by the playlist it’s displaying. Then, a user could toggle back and forth between viewing two different track lists, while preserving the sort state within each list separately.
In our example scenario, our app is simple enough so far that we only need to manage state for a single global track list; we can use the singleton strategy and keep the table limited to a single row. The table will look like this:
component__TrackList
| id | sortProperty | sortDirection |
|---|---|---|
| SINGLETON | name | asc |
In our code, we can use Riffle’s useComponentState hook to access getter and setter functions to manipulate the state. This hook resembles React’s useState hook but is implemented in terms of simple database queries. The getters are reactive queries that incorporate the key for this component instance; the setters are syntax sugar for update statements which also incorporate the component key.
import { useComponentState } from 'riffle'
const TrackListSchema = {
componentType: "TrackList",
columns: {
sortProperty: "string",
sortDirection: "string"
}
}
const TrackList = () => {
const [state, set] = useComponentState(TrackListSchema, { key: "singleton" })
const tracks = useQuery(tracksQuery)
return <table>
<thead>
<th onClick={set.sortProperty("name")}>Name></th>
<th onClick={set.sortProperty("album_name")}>Album></th>
<th onClick={set.sortProperty("artists")}>Artists</th>
</thead>
<tbody>
{tracks.map(track => <tr>
<td>{track.name}</td><td>{track.album}</td><td>{track.artist}</td>
</tr>)}
</tbody>
</table>
}Next, we need to actually use this state to sort the tracks. This query doesn't just read the current value; it creates a reactive dependency. It's a bit hard to read because we're relying on string interpolation, since SQLite's dialect of SQL has no way to dynamically control the sort order using a relation. With a different language than SQL, one could imagine writing this in a more relational way that doesn't involve string interpolation at all. We can interpolate the sort property and sort order into a SQL query that fetches the tracks:
// Define SQL query for sorted tracks based on original tracks query
const sortedTracks = db.query((get) => sql`
select *
from (${get(tracksQuery.queryString)}) -- use tracks as a subquery
order by ${get(state.sortProperty)} ${get(state.sortOrder)}
`)This new query for sorted tracks depends on the local component state, as well as the original tracks query:
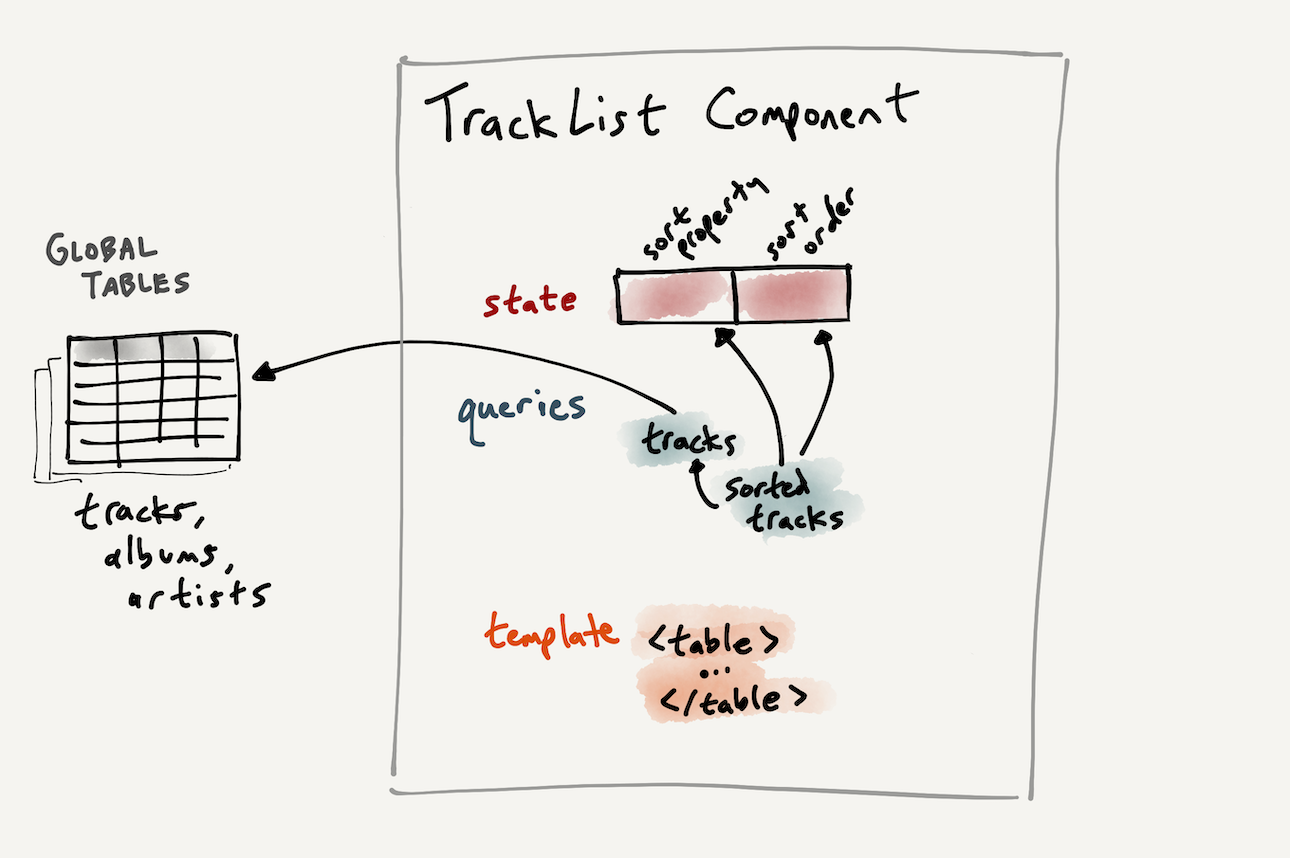
Now if we populate the list of tracks from this query, when we click the table headers, we see the table reactively update:
Of course, this is functionality that would be easy to build in a normal React app. What have we actually gained by taking the Riffle approach here?
First, it’s simpler to understand what’s going on in the system, because the system has structured dataflow at runtime which exposes the provenance of computations. If we want to know why the tracks are showing up the way they are, we can inspect a query, and transitively inspect that query’s dependencies, just like in a spreadsheet.
Second, we can achieve more efficient execution by pushing computations down into a database. For example, we can maintain indexes in a database to avoid the need to sort data in application code, or manually maintain ad hoc indexes.
Finally, UI state is persistent by default. It’s often convenient for end-users to have state like sort order or scroll position persisted, but it takes active work for app developers to add these kinds of features. In Riffle, persistence comes for free, although ephemeral state is still easily achievable by setting up component keys accordingly.
Full text search
Next, let’s add a search box where the user can type to filter the list of tracks by track, album, or artist name. We can add the current search term as a new column in the track list’s component state:
component__TrackList
| id | sortProperty | sortDirection | searchTerm |
|---|---|---|---|
| SINGLETON | name | asc | Timberlake |
<input
type="text"
value={state.searchTerm}
onChange={(e) => set.searchTerm(e.target.value)} />We can then connect an input element to this new piece of state in the database. We use a standard React controlled input, which treats the input element as a stateless view of our app state rather than an inherently stateful DOM element.
Next, we need to wire up the search box to actually filter the list of tracks. SQLite has an extension that we can use to create a full text index over our tracks table; we’ll call our index tracks_full_text. Then we can rewrite our query to use this index to filter the query based on the current search term in the search box:
const filteredTracks = db.query((get) => {
let query = sql`select * from tracks_full_text`
// If search term is present, filter using full text index
if(state.searchTerm() !== "") {
query = sql`${query} where tracks_full_text match "${get(state.searchTerm)}*"`
}
return query
})Revisiting our graph of dependent queries, there’s now a new layer:
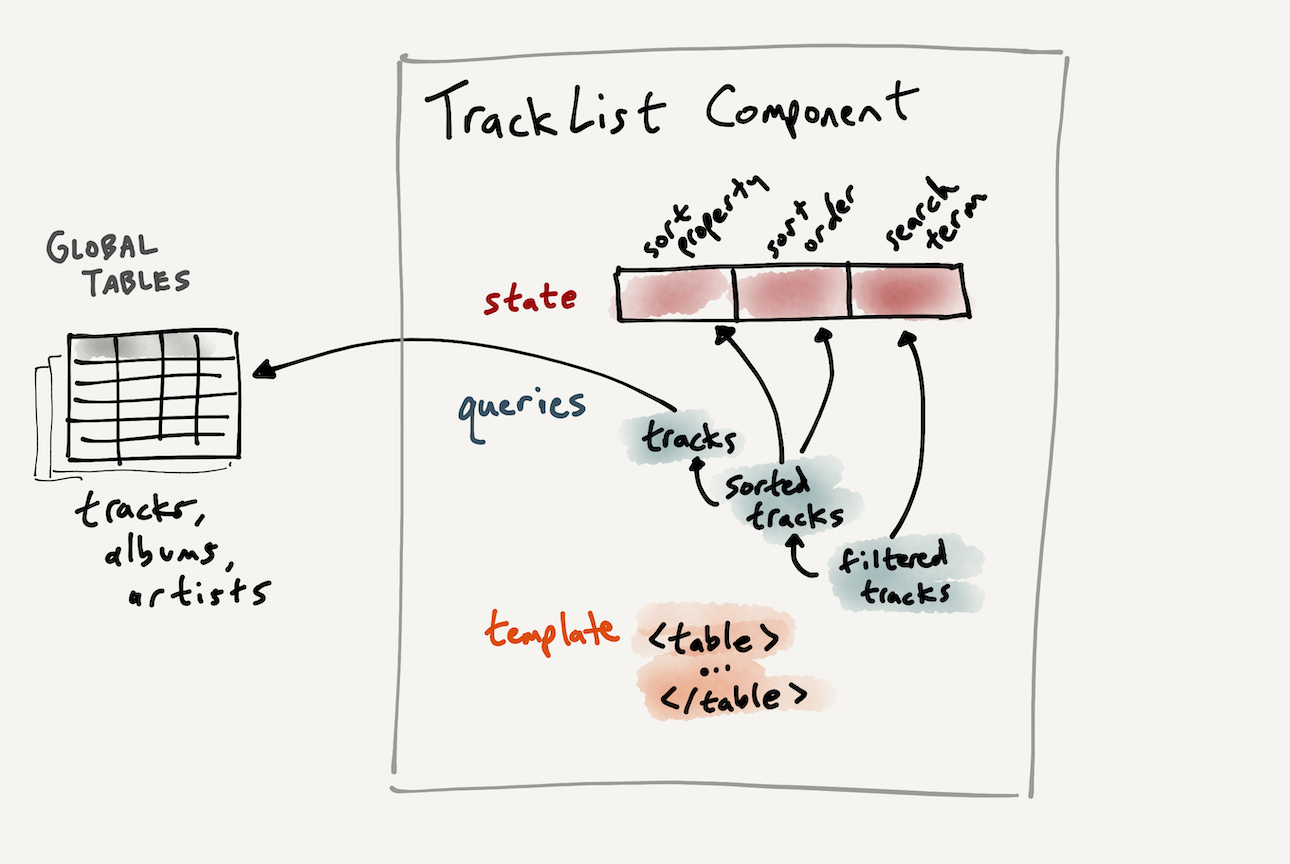
Now, when the user types into the search box, their search term appears and filters the list of tracks:
Interestingly, because we’re using a controlled component, every keystroke the user types must round trip through the Riffle database before it is shown on the screen, which imposes tight constraints on database latency: ideally we want to finish updating the input and all its downstream dependencies within a few milliseconds.
It’s unusual to send user input through the database before showing it on the screen, but there’s a major advantage to this approach. If we can consistently achieve this performance budget and refresh our reactive queries synchronously, the application becomes easier to reason about, because it always shows a single consistent state at any point in time. For example, we don’t need to worry about handling the case where the input text has changed but the rest of the application hasn’t reacted yet.
In our experience so far, SQLite can run most queries fast enough to make this approach work. (We discuss what can be done in cases where it isn’t fast enough later.) As another example of how fast a local datastore can be, we can store the currently selected track in the database. Selecting tracks with the mouse or keyboard feels responsive, even though it’s round-tripping through the database every time the selection changes:
Virtualized list rendering
Personal music collections can get large—it’s not uncommon for one person to collect hundreds of thousands of songs over time. With a large collection, it’s too slow to render all the rows of the list to the DOM, so we need to use virtualized list rendering: only putting the actually visible rows into the DOM, with some buffer above and below.
In our current prototype, we had to throttle database writes so the new scroll state only gets written to the database once every 50ms. In our findings we discuss sources of these performance limitations; in a future system we'd like to remove this throttling.With Riffle, implementing a simple virtualized list view from scratch only takes a few lines of code. We start by representing the current scroll position in the list as a new state column on the track list component, scrollIndex. As the user scrolls, we use an event handler on the DOM to update this value, essentially mirroring the stateful scroll position of the DOM into the database.
import { throttle } from 'lodash'
const handleScrollTopChanged =
throttle(scrollTop => {
const scrollIndex = Math.floor(scrollTop / TRACK_HEIGHT)
set.scrollIndex(scrollIndex)
}, 50)
//...
<div onScrollCapture={e => handleScrollTopChanged(e.target.scrollTop)}>
{// ... track list contents}
</div>Then, we can write a reactive database query that uses this scroll index state and only returns the rows around the currently visible window, using a SQL limit and offset . We can then do a little more math to position those rows the appropriate distance from the top of the container.
const PAGE_SIZE = 40 // size of one page in the UI
const PAGE_BUFFER = 100 // extra rows to load on either side
const filteredPagedTracks = db.query((get) => {
const startIx = parseInt(get(state.scrollIndex)) - PAGE_BUFFER
return sql`
select * from ${filteredTracks} as tracks
limit ${PAGE_SIZE + (2 * PAGE_BUFFER)} offset ${startIx}
`
},This simple approach to virtualized list rendering turns out to be fast enough to support rapid scrolling over a large collection of tracks:
Because all the data is available locally and we can query it quickly, we don’t need to reason about manual caches or downloading paginated batches of data; we can simply declaratively query for the data we want given the current state of the view.
Building a complex app?
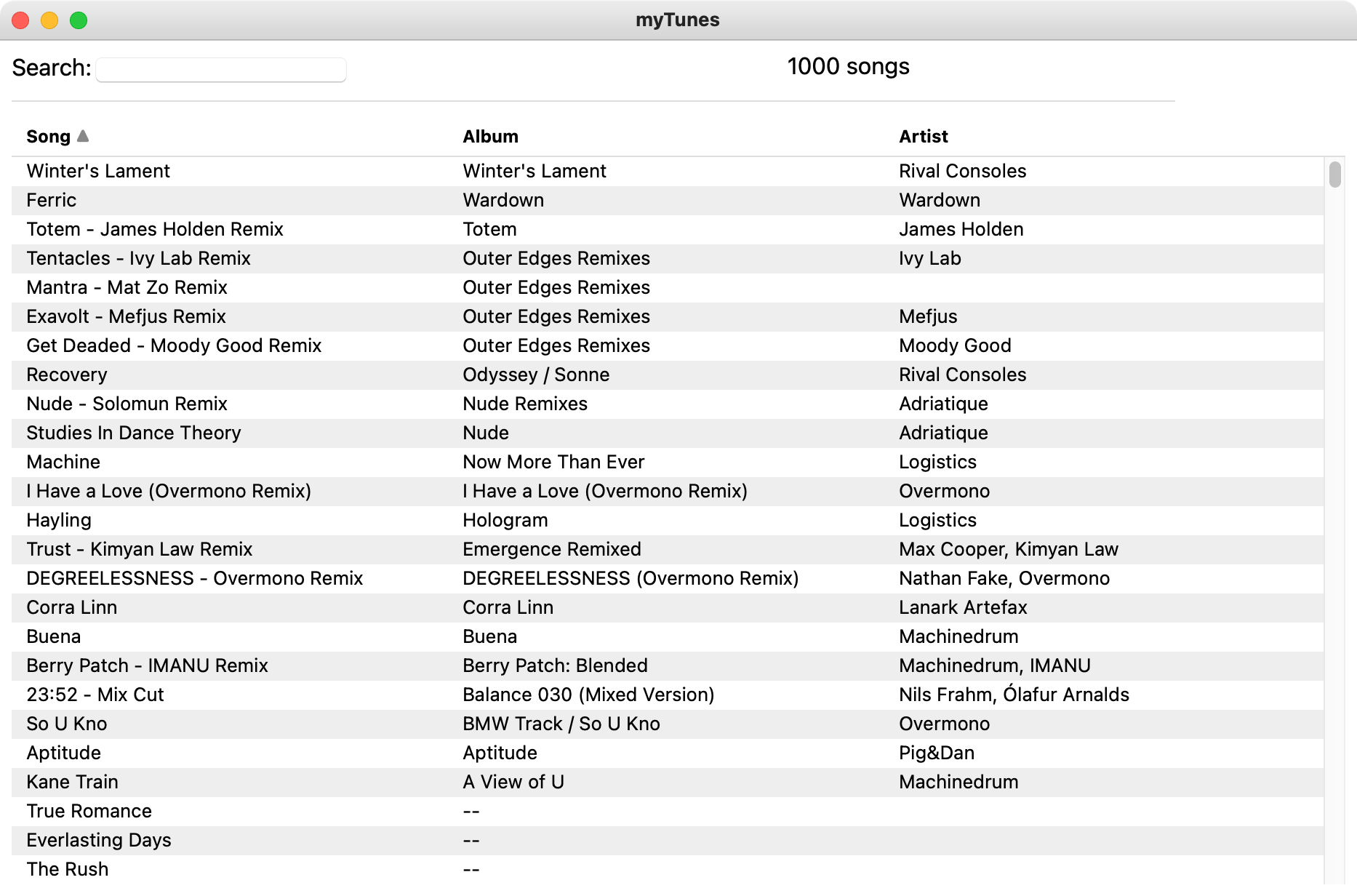
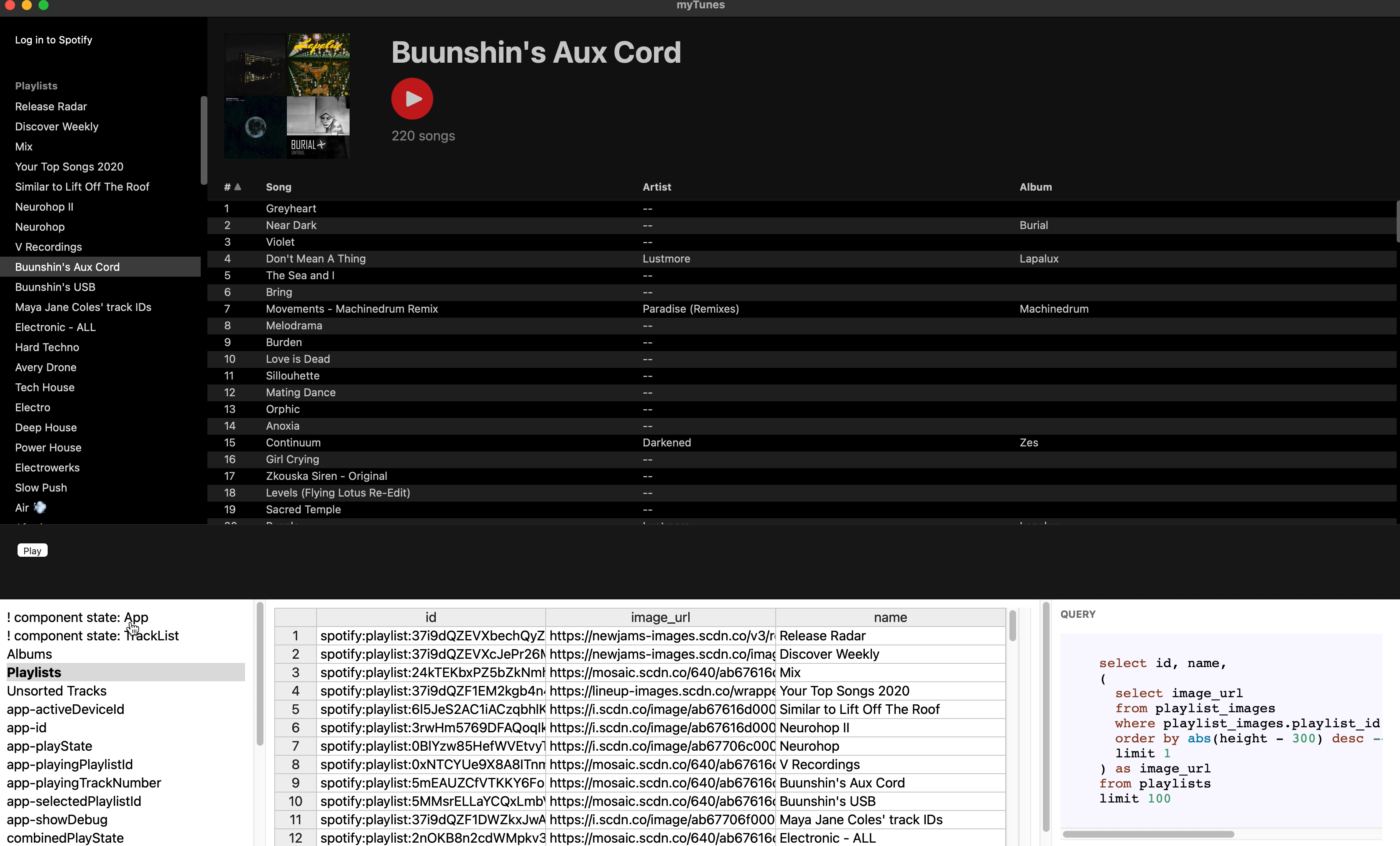
So far we’ve shown a very simple example, but how does this approach actually scale up to a more complex app? To answer this question, one of us has been using a version of Riffle to build a full-featured music manager application called MyTunes. It has a richer UI for playlists, albums, artists, current play state, and more. It also syncs data from Spotify and streams music via their API, so we’ve been using it as a daily music player in place of Spotify. Here’s a recent screenshot:
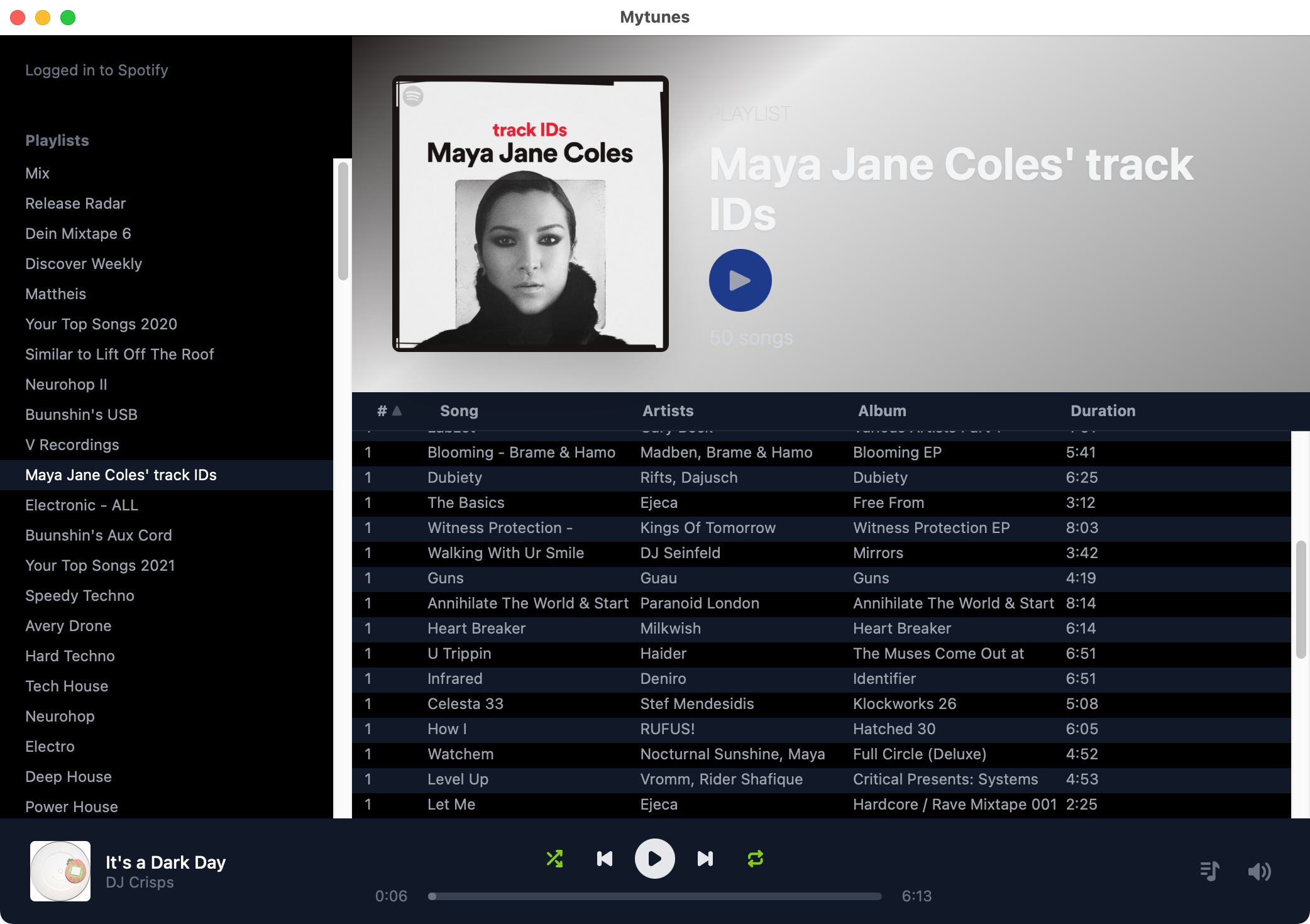
Building a more complex app has revealed several challenges. One issue has been integrating Riffle’s reactive queries with React’s own reactivity in a way that doesn’t create confusion for a developer. Another challenge has been maintaining low latency even as the app grows in complexity. Finally, there are many details which matter greatly for day-to-day developer experience, including API design, TypeScript type inference for query results, and schema/migration management.
We’re still working through many of these challenges, so we wouldn’t claim yet that our prototype offers a great experience for developing a full-featured app. However, we have been encouraged that, so far, the overall reactive relational model does seem viable for scaling beyond a tiny toy app.
Findings
Here are some reflections from working with our prototype system.
Structured queries make it easier to understand an app
The Riffle model produces a highly structured app. Each component contains:
- local relational state
- reactive queries that transform data
- a view template for rendering DOM nodes and registering event handlers
These components are organized into a tree, where components can pass down access to their queries (and state) to their children:
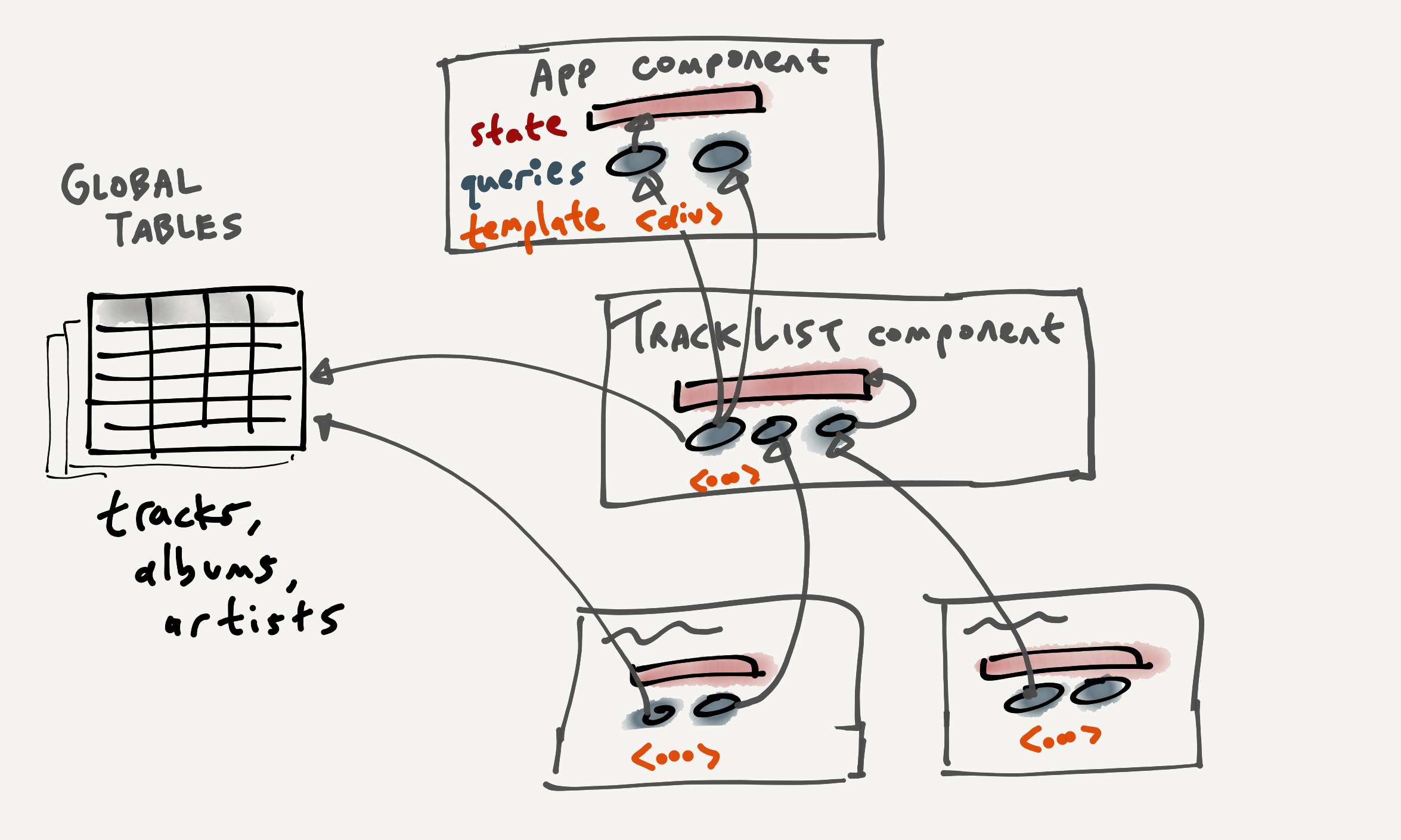
In some sense, the view template is also a “query”: it’s a pure function of the data returned by the queries, and its expressed in a declarative, rather than imperative style! So, we can view the queries and template together as a large, tree-structured view of the data—the sources are the base tables, the sinks are the DOM templates, and the two are connected by a tree of queries. All dependencies are known by the system at runtime.
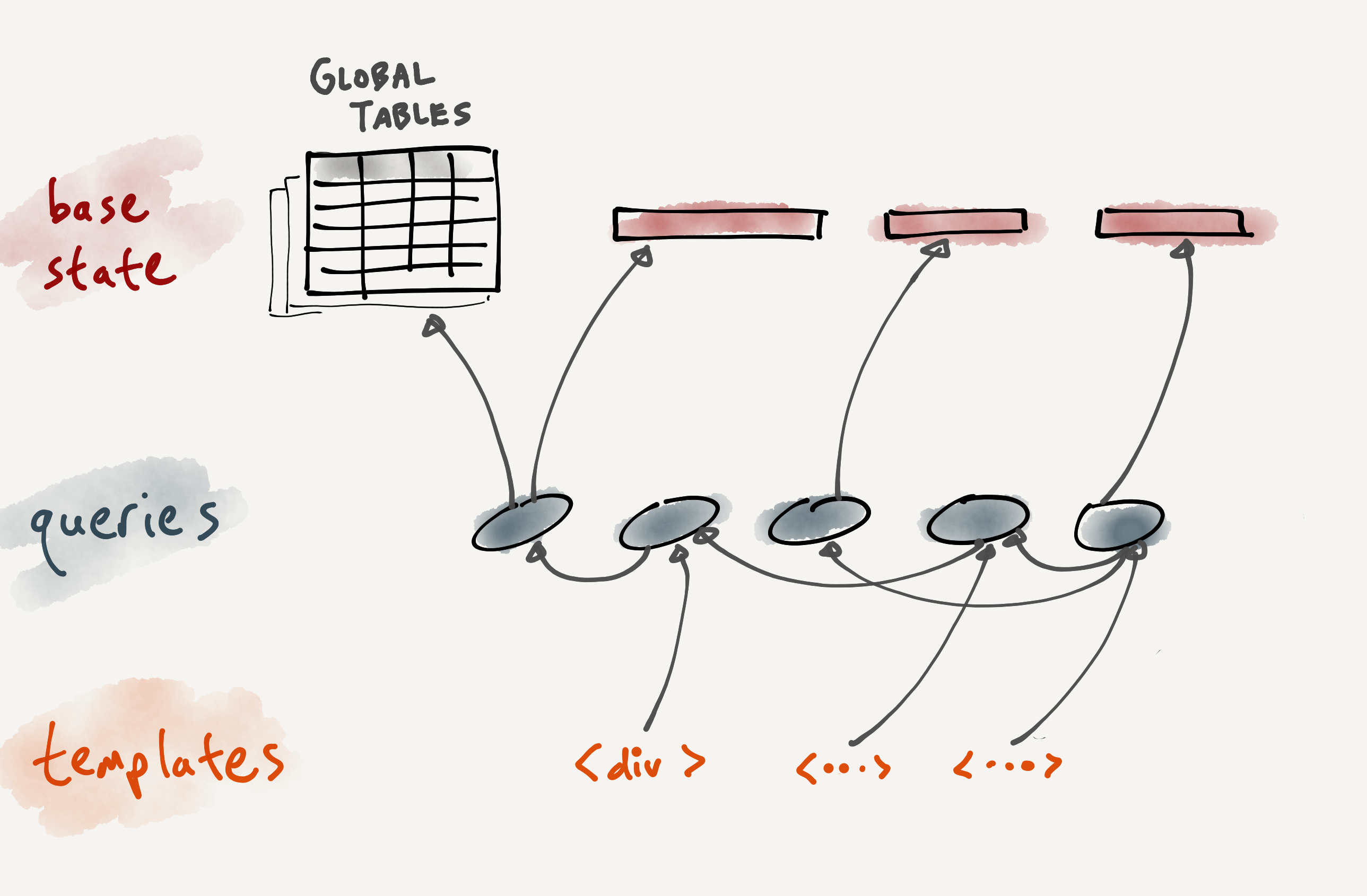
In general, we found that thinking about our app in these terms made it easier to reason about behavior. You could imagine the pictures above being shown live as a visual debugger view. We spent a few days prototyping a very primitive debugger:
This debugger pane shows ① on the left, a list of various database tables (spanning both app state and UI state), ② in the middle, live views of tabular data, ③ on the right, live views of SQL queries which are being dynamically generated at runtime.
Even this basic debugger proved highly useful, because it enabled us to ask “why is this UI element showing up this way?”, and trace back the chain of computations through the tree of queries. It reminded us of debugging a spreadsheet, where pure formulas can always explain the contents of the sheet. Since our queries are tightly bound to UI components, being able to look at the “data behind the UI” made it much easier to hunt down the particular step in the transformation pipeline that had the bug.
This debugger UI isn't yet rich enough to fully deliver on the promise, but we're optimistic that the underlying structure of the state model will make it easier to develop full-featured debug views. One example of a thoughtful interface for debugging in a dataflow graph is Observable's dependency visualization.
It’s interesting to compare this set-wise debugging from debuggers in imperative programs. Imperative debuggers can iterate through a for-loop (or equivalently, a map) but we usually don’t see all the data at once. The pervasive use of relational queries seems to be a better fit for debugging data-intensive programs, although we feel that we’ve only scratched the surface of the problem.
Data-centric design encourages interoperability
One quality we found particularly intriguing in our prototype was the ability to control the app from the outside, using the database as an intermediary.
When using the desktop version of our app, the database is stored in a SQLite file on disk which can be opened in a generic SQL tool like TablePlus. This is helpful for debugging, because we can inspect any app or UI state. But we can also go even further: we can modify the UI state of the app! In the video below, we can see the UI reacts as we use TablePlus to edit a search term and change the sort order:
In TablePlus, the user must explicitly commit each change by pressing Cmd+S. After the user commits the change, the music app reacts quickly.This kind of editing doesn’t need to be done manually by a human using a generic UI; it could also be done programmatically by a script or an alternate UI view. We’ve effectively created a data-centric scripting API for interacting with the application, without the original application needing to explicitly work to expose an API. We think this points towards fascinating possibilities for interoperability.
Since the introduction of object-oriented programming, most interoperability has been “verb-based”: that is, based on having programs call into each other using APIs. Indeed, new programmers are often taught to hide data behind APIs as much as possible in order to encapsulate state. Unfortunately, verb-based APIs create an unfortunate n-to-n problem : every app needs to know how to call the APIs of every other app. In contrast, data-based interoperability can use the shared data directly: once an app knows how to read a data format, it can read that data regardless of which app produced it.Many users who are familiar with standard UNIX tools and conventions speak wistfully of “plain text” data formats, despite its disadvantages. We feel that plain text is an unfortunate way to store data in general, but recognize what these users long for: a source of truth that is legible outside of the application, possibly in ways that the application developer never anticipated. As we saw in our TablePlus demo, data-based interoperability provides these advantages while also providing the advantages of a structured file format.
We’ve also explored this idea for integrating with external services. In the full MyTunes app, we’ve built features for playing music on Spotify; normally this would involve the application making imperative calls to the Spotify API. However, getting these imperative calls are tricky—for example, what happens if around the same time the user hits Play in MyTunes, and Pause in the Spotify app itself? We’ve taken a different approach of modeling this as a problem of shared state: both our application and Spotify are reading/writing from the same SQLite database. When the user performs an action, we write that action to the database as an event, which is then synced by a background daemon using the imperative Spotify APIs. Conversely, when something happens in Spotify, we write an event to our local database, and the app updates reactively as it would with an app-created write. Overall, we think shared state is a better abstraction than message passing for many instances of integrations with external services.
Users and developers benefit from unified state
We found it nice to treat all data, whether ephemeral “UI data” or persistent “app data”, in a uniform way, and to think of persistence as a lightweight property of some data, rather than a foundational part of the data model.
We were frequently (and unexpectedly) delighted by the persistent-by-default UI state. In most apps, closing a window is a destructive operation, but we found ourselves delighted to restart the app and find ourselves looking at the same playlist that we were looking at before. It made closing or otherwise “losing” the window feel much safer to us as end-users.
Admittedly, this persistence was also frustrating to us as developers at times: restarting the app didn’t work as well when the buggy UI state persisted between runs. We often found ourselves digging through the database to delete the offending rows. This did lead to another observation, though: in this model, we can decouple restarting the app from resetting the state. Since the system is entirely reactive, we could reset the UI state completely without closing the app.
Another challenge was fitting compound UI state like nested objects or sequences into the relational model. For now, we’ve addressed this challenge by serializing this kind of state into a single scalar value within the relational database. However, this approach feels haphazard, and it seems important to find more ergonomic relational patterns for storing common kinds of UI state.
SQL is a mediocre language for UI development
We were initially very enthusiastic about unlocking the power of SQL in a web app. We found a lot to like in SQL: the relational model provides a lot of advantages, query optimizers are very powerful, and a large number of people, including many who aren’t “software developers” can understand and even write it.
Nonetheless, SQL was a consistent thorn in our side during this project. The deficiencies of SQL are well-known, so we won’t belabor them here. A few key pain points for us were:
- Standard SQL doesn’t support nesting, even in the projection step (i.e., what describes the shape of the results). There are various extensions to SQL that support nesting, but many of them are not that good and the good ones are not widely available. We’re big fans of data normalization, but it’s very convenient to nest data when producing outputs.
- SQL syntax is verbose and non-uniform. SQL makes the hard things possible, but the simple things aren’t easy. Often, making small changes to the query requires rewriting it completely.
- SQL’s scalar expression language is weird and limited. Often, we wanted to factor out a scalar expression for re-use, but doing this in SQLite was annoying enough that we didn’t do it often.
- SQL doesn't have good tools for metaprogramming and changing the shape of a query at runtime: e.g., adding or removing a `where` filter clause depending on some data in the database. This forced us to often resort to using JavaScript string interpolation.
We view these issues as shortcomings of SQL in particular, and not the idea of a relational query language in general. Better relational languages could make UI development more ergonomic and avoid the need for clumsy ORM layers. Also, the prospect of replacing SQL seems more realistic in a domain like frontend UI where SQL hasn’t yet taken hold in the first place.
While we tried to stick to well-known technologies like SQL in our prototype, we are excited about the potential of newer relational languages like Imp and Datalog.
Performance is a challenge with existing tools
In principle, declarative queries should be a step towards good app performance by default. The application developer can model the data conceptually, and it is up to the database to find an efficient way to implement the read and write access patterns of the application. In practice, our results have been mixed.
On the bright side, the core database itself has been mostly fast. We've traced slow queries back to the limitations of SQLite's query optimizer. For example, it doesn't optimize across subquery boundaries, but we made extensive use of subqueries to modularize our queries. Also, it only does simple nested loop joins, which can be slow for joins on large tables. As an experiment, we tried replacing SQLite with DuckDB, a newer embedded database focused on analytical query workloads with a state-of-the-art optimizer. We saw the runtimes of several slow queries drop by a factor of 20, but some other queries got slower because of known limitations in their current optimizer. Ultimately we plan to explore incremental view maintenance techniques so that a typical app very rarely needs to consider slow queries or caching techniques. Even running in the browser using WebAssembly, SQLite is fast enough that most queries with a few joins over a few tens of thousands of rows complete in less than a millisecond. We've had some limited exceptions, which we've worked around for now by creating materialized views which are recomputed outside of the main synchronous reactive loop.
However, outside of the database proper, we’ve encountered challenges in making a reactive query system that integrates well with existing frontend web development tools in a performant way.
One challenge has been inter-process communication. When the reactive graph is running in the UI thread and the SQLite database is on a web worker or native process, each query results in an asynchronous call that has to serialize and deserialize data. When trying to run dozens of fast queries within a single animation frame, we’ve found that this overhead can become a major source of latency. One solution we’re exploring is to synchronously run SQLite in the UI thread, and to asynchronously mirror changes to a persistent database.
Another challenge has been integrating with React. In an ideal world, a write would result in Riffle fully atomically updating the query graph in a single pass, and minimally updating all the relevant templates. Some React alternatives like Svelte and SolidJS take a different approach: tracking fine-grained dependencies (either at compile-time or runtime) rather than diffing a virtual DOM. We think this style of reactivity could be a good fit for Riffle, but for now we've chosen to prototype with React because it's the UI framework we're most familiar with. However, to preserve idiomatic React patterns (like passing component dependencies using props), we've found that it sometimes takes a few passes to respond to an update—a write occurs, Riffle queries update, React renders the UI tree and passes down new props, Riffle queries are updated with new parameters, then React renders the tree again, and so on. We're still finding the best patterns to integrate with React in a fast and unsurprising way.
Rendering to the DOM has been another source of performance problems. We’ve seen cases where the data for a playlist of tracks can be loaded in <1ms, but the browser takes hundreds of milliseconds to compute the CSS styles and layout.
We think there are reasonable solutions to each of these performance challenges in isolation, but we suspect the best solution is a more integrated system that doesn’t build on existing layers like SQlite and React.
Migrations are a challenge
In our experience, migrations are a consistent pain when working with SQL databases. However, our prototype created entirely new levels of pain because of the frequency with which our schema changed.
In a more traditional architecture, state that's managed by the frontend gets automatically discarded every time the program is re-run. Our prototype stores all state, including ephemeral UI state that would normally live exclusively in the main object graph, in the database, so any change to the layout of that ephemeral state forced a migration. This problem is reminiscent of some of the challenges of Smalltalk images, where code was combined with state snapshots. In most cases, we chose to simply delete the relevant tables and recreate them while in development, which essentially recreates the traditional workflow with ephemeral state.
Of course, Riffle is not the first system to struggle with migrations; indeed, one of us has already done extensive work on migrations for local-first software. We believe that making migrations simpler and more ergonomic is a key requirement for making database-managed state as ergonomic as frontend-managed state.
Towards a more radical approach
So far, we’ve argued that using reactive relational queries to store and reshape data in an app has simplified the stack. However, if we zoom out and look at all the steps involved in building an app, we’ll realize that we’ve actually only addressed one slice of the problem so far.
In this section, we describe a more radical approach to spreading reactive relational queries further up and down the stack. These ideas are more speculative and we haven’t yet substantiated them with concrete implementations, but we think they’re worth pursuing.
View templates as queries
So far, in our prototype, we’ve delegated rendering to React. The database’s responsibility ends at updating derived data views; React is responsible for rendering those into view templates and applying updates to the DOM:
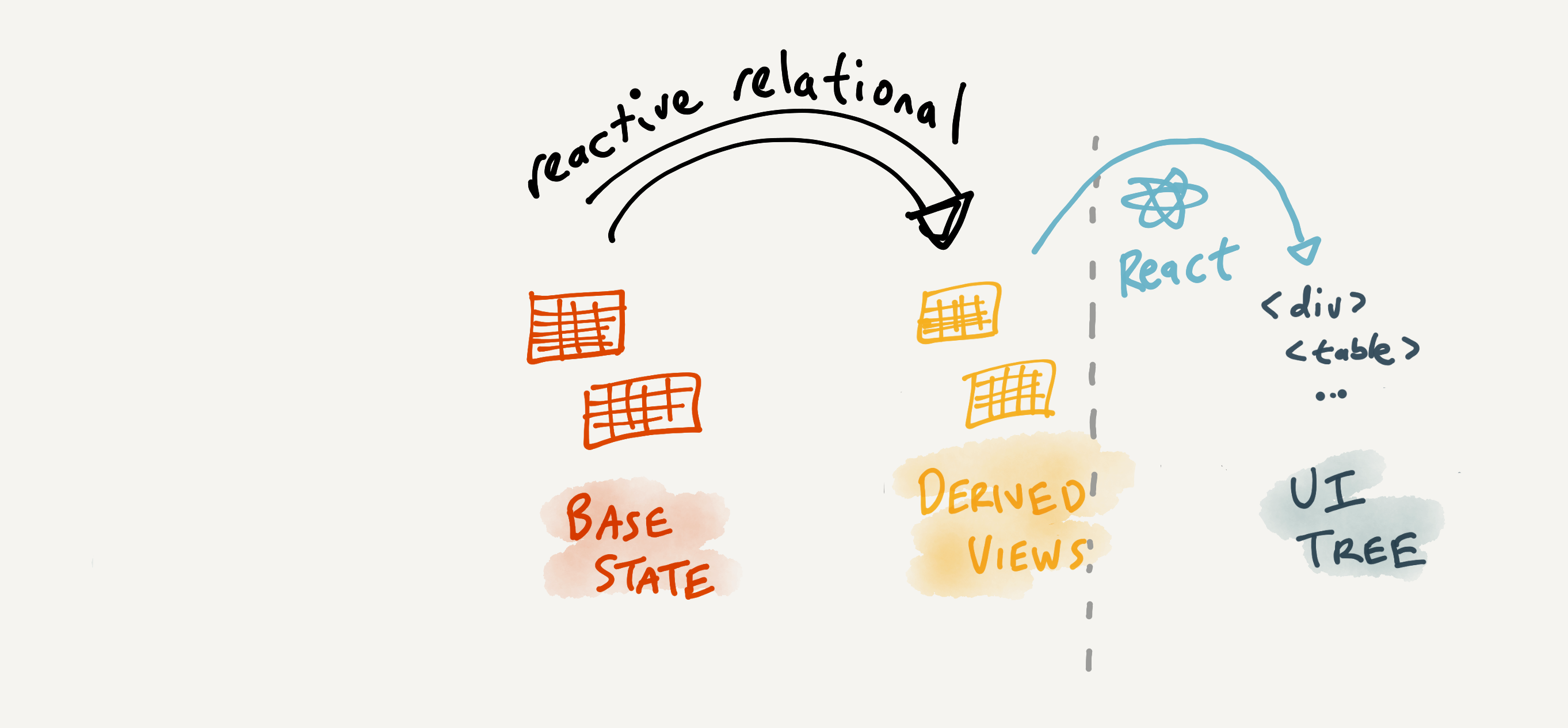
This has been great for rapid prototyping, but the combination of these two systems causes problems. It’s harder to understand behavior as a whole, and the system is slower than it needs to be. What if we removed React (or any other rendering library) from the stack, and used reactive relational queries to directly render view templates?
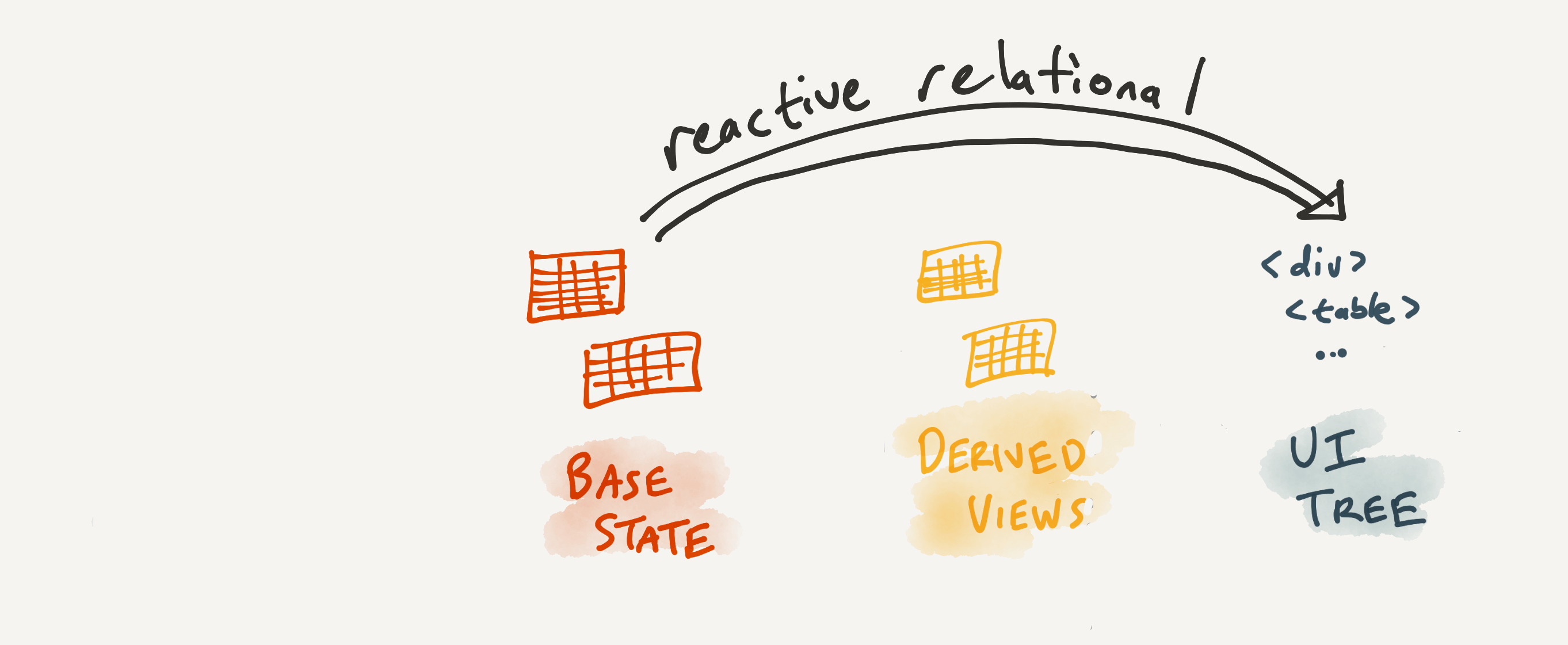
It’s difficult to imagine doing this in a language like SQL, but with a different relational language and a careful approach to templating, it’s plausible. Jamie Brandon has explored this direction in his work on Relational UI.
CRDTs as queries
There’s yet another part of the stack that we’ve mostly ignored in this essay. In many collaborative apps, we need to turn events representing user actions into some base state that’s seen by all users. One common approach to this step is to use Conflict-Free Replicated Data Types (CRDTs), which ensure that all users see the same state even if their events got applied in different orders:
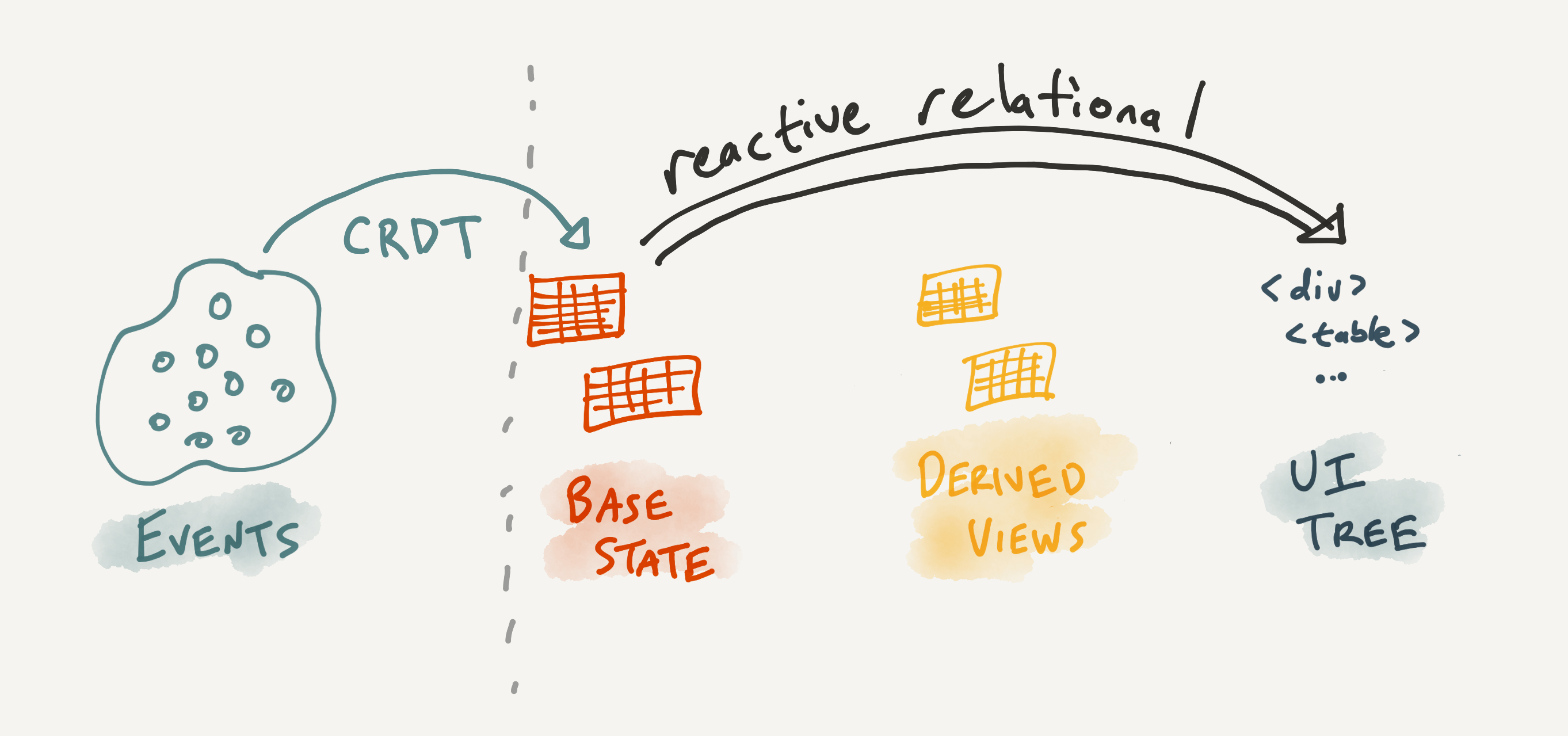
Typically, CRDTs are developed for maintaining specific kinds of data structures, by reasoning very carefully about commutativity properties. However, there’s an elegant idea of representing CRDTs in a more general way: as a declarative, relational query that turns a set of events into a final state—as seen in Martin Kleppmann’s implementation of a text CRDT using Datalog. This suggests it might be possible to subsume CRDTs into the full-stack relational query as well:
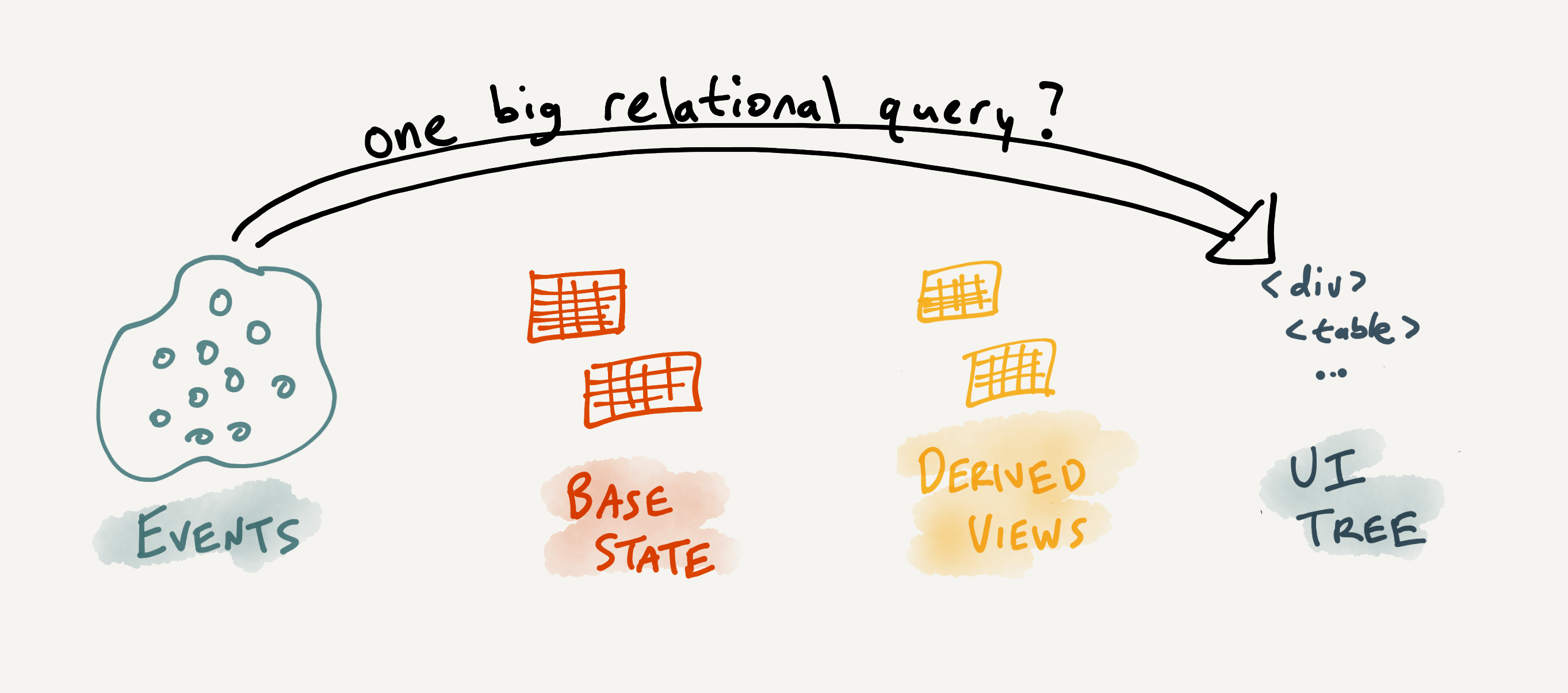
Taken to the extreme, we’ve ended up with a strange model of an interactive app, as a sort of full-stack query. Users take actions that are added to an unordered set of events, and then the DOM minimally updates in response. The entire computation in between is handled by a single relational query.
What might compressing the stack into a query get us?
This may seem like an elegant concept, but there’s a natural question of whether it would actually lead to any progress in our quest to make app development simpler, faster, and more powerful. We think that the key benefit would be making it easier to reason across layers of the stack.
For example, let’s consider performance. Users are exquisitely sensitive to even small amounts of latency, and we believe that low latency is a key property of the types of creative tools that we’re excited about. A key challenge in building performant apps is performing incremental updates: it’s often much easier to describe how to build the UI from scratch than to figure out how it must update in response to a new event, but it’s often too expensive to rebuild the UI from scratch every frame as in immediate-mode GUI tools. Indeed, a key lesson from React and other virtual DOM-based tools is finding a way to automatically transform a build-from-scratch description of the UI into an incremental one.
In the past twenty years, researchers in the programming languages and database communities have developed various tools for automatically incrementalizing computation. Many of these techniques are attempts to solve the incremental view maintenance problem for relational databases, where a view of the data is dynamically maintained as new writes occur. Incremental view maintenance is the problem of updating the results of a query over some data as it changes. Simple indexes can be viewed as a sort of view--the data sorted by the index key--that is especially easy to maintain. The basic problem has been studiedfordecades in the database research community. Recently, new approaches to the incremental view maintenance problem have drawn from general incremental computing frameworks, like differential dataflow.
If the UI can be expressed in a way that is friendly to one of these automated incremental maintenance, perhaps as a declarative view of the data, we might be able to express user interfaces in a declarative, build-from-scratch way but obtain the performance benefits of incremental updates. Other efforts in this space, like the Incremental and inc-dom libraries, have shown considerable success in these directions.
While this seems like a purely technical benefit, we also believe that there are conceptual advantages to uniformity in the user interface stack. Many systems for incremental maintenance work by tracking data provenance: they remember where a particular computation got its inputs, so that it knows when that computation needs to be re-run. We believe that understanding data provenance is also a fundamental tool in understanding app behavior, for both app developers trying to debug the app and end users who are trying to extend it.
Imagine a browser-style developer console that allows you to click on a UI element and see what component it was generated from. In a system with end-to-end provenance, we could identify how this element came to be in a much deeper way, answering questions not just questions like “what component template generated this element?” but “what query results caused that component to be included?” and even “what event caused those query results to look this way?“. We saw an early example of this in our query debugger view, but we believe that this can be taken much further. In many ways, data provenance tracking seems like a key step towards fulfilling the vision of Whyline, where any piece of an app can be inspected to determine why it’s in that state.
Where we’re going
We started this project wondering how the local-first availability of an app’s data could change and simplify app development. At this point, we’re left with more questions than answers. However, we see the outline of an approach where user interfaces are expressed as queries, those queries are executed by a fast, performant incremental maintenance system, and that incremental maintenance gives us detailed data provenance throughout the system. Together, those ideas seem like they could make app development radically simpler and more accessible, possibly so simple that it could be done “at the speed of thought” by users who aren’t skilled in app development.
We find a lot of inspiration from tools like spreadsheets, arguably the origin of the reactive programming model, and Airtable, which draws inspiration from the relational model. Airtable is by far the most polished expression of the relational model in a tool aimed at end users. In our experience, users with no technical background besides computer office skills can be highly productive in Airtable after just a few months. Nonetheless, Airtable has some significant limitations. Its query facilities are limited to what can be expressed in the view UI, and don’t come close to expressing the full power of relational queries—for instance, it doesn’t support general joins, or even nested filter predicates. Also, its performance degrades rapidly when a single database approaches the kinds of medium-sized data sets that we are most interested in, and it has a hard limit of 50,000 records per base. These tools are highly productive in their domains; in our experience, they are more productive than traditional developer tools even for skilled software engineers. Nonetheless, they have significant technical and conceptual limitations; you can’t use Airtable to write iTunes. We hope that by taking a step back and developing some key abstractions, we can achieve the full expressive power of “general purpose” programming tools and simplify them dramatically, for experts and novices alike.
We’re excited by this potential, and even more excited by the possibility that we might already have the basic technological pieces to make that vision a reality.
We’d love your feedback: we’re reachable by email at glitt@mit.edu and schiefer@mit.edu, and on Twitter at @geoffreylitt and @nschiefer!
We’re grateful for helpful feedback from Max Bittker, Jamie Brandon, Sam Broner, Mike Cafarella, Adam Chlipala, Jonathan Edwards, Josh Horowitz, Adam Jermyn, David Karger, Martin Kleppmann, Kevin Lynagh, Sam Madden, Rob Miller, Josh Pollock, Jalex Stark, Michael Stonebraker, Peter van Hardenberg, the MIT Software Design Group, and the MIT Data Systems Group as we developed the ideas in this essay. We’re also grateful to Maxwell Brown for helping to build the data import system for MyTunes. Geoffrey Litt was supported by an NSF GRFP Fellowship and the NSF SaTC Program (Award 1801399). Nicholas Schiefer was supported by a Simons Investigator Award.